This is the fourth and final part of this series by Shrikant Talageri on India’s unique place in the world of numbers and numerals and its implications for the Out-of-India Theory of Indo-European Origins.
C-VIII. HISTORICAL IMPLICATIONS OF THE INDO-ARYAN NUMBER SYSTEM:
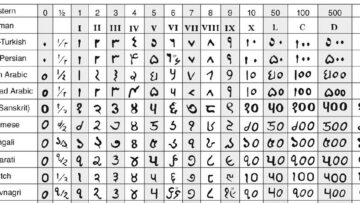
The number systems as found in the different languages in India show a great range and variety. We do not find the most uncommon types like the sexagesimal (based on 60, found in the Masai language in Africa), and the quindecimal (based on 15, found in the Huli language of Papua), but within the more common systems, the vigesimal (based on 20), and decimal (based on 10), we have every possible variety: see the difference above between the number systems in the closely related Santali and Turi languages where, after the initial four numbers 1-4, there is nothing in common, and Santali has a purely decimal system while Turi has a purely vigesimal system with a subset of five.
The interesting thing is that an analysis of the development of number systems in the world presents us with an interesting point about the origin and spread of the Indo-European languages from their original homeland, pointing towards the geographical location of that homeland. For the purpose of the discussion to follow, which is about the development of the Indo-European number system, we will leave out the language families of the New World and some isolated language families in the Old World (i.e. the Australian, Papuan, Amerindian, and also Andamanese, as well as the interior families of Africa: Khoisan, Niger-Congo and Nilo-Saharan, and also Eskimo-Aleut, which straddles the northernmost parts of both the Old and New Worlds, from Greenland to Alaska and the easternmost tips of Siberia), since they are not relevant to this question.
It will be seen that the decimal system dominates in the most widely spoken and distributed language families in the Old World (Indo-European, Semito-Hamitic, Sino-Tibetan, Uralo-Altaic, Austronesian, Dravidian), and the vigesimal system is found in the more isolated families (in the three language-isolate families, Basque, Burushaski and Ainu, and in Caucasian).
It is also likely that the vigesimal system was the original system in the Austric family: we have the system in Turi (in its earliest form, with a clear subset of 5), and in Savara and Nicobarese and perhaps originally in Khmer as well (among the languages examined by us here). The Vietnamese language was clearly influenced by its Sino-Tibetan family neighbours in developing a decimal system: note that it also has a tonal-system and monosyllabled words like most of its major Sino-Tibetan neighbour languages. Santali was also probably influenced by its Indo-Aryan and Dravidian neighbours, and Khasi by its Sino-Tibetan and Indo-Aryan neighbours, in developing a decimal system. It may be noted that Turi (mead, pea, punia), Santali (mit’, pɛ, pon), Khmer (muәy, bәy, buәn) and Vietnamese (mot _ , ba, bôn
_ , ba, bôn ) have a close correspondence in the numbers for 1, 2 and 4, but not beyond that, and Turi has basic unit number words only upto 4 (all of which could be pointing to an original subset of 5). A reverse influence is seen in the originally Austric-speaking areas of eastern India, where neighboring Sino-Tibetan languages like Sikkimese and Garo have developed vigesimal systems. We also saw how the (Indo-European) Celtic languages like Welsh and Irish developed vigesimal systems in what probably was originally the ancient area of the Basque family (although Irish also retained parallel decimal word-names for the tens), while French was influenced enough to develop words like quatre-vingts for 80 and soixante-onze etc. for 71 etc..
) have a close correspondence in the numbers for 1, 2 and 4, but not beyond that, and Turi has basic unit number words only upto 4 (all of which could be pointing to an original subset of 5). A reverse influence is seen in the originally Austric-speaking areas of eastern India, where neighboring Sino-Tibetan languages like Sikkimese and Garo have developed vigesimal systems. We also saw how the (Indo-European) Celtic languages like Welsh and Irish developed vigesimal systems in what probably was originally the ancient area of the Basque family (although Irish also retained parallel decimal word-names for the tens), while French was influenced enough to develop words like quatre-vingts for 80 and soixante-onze etc. for 71 etc..
The point here is that the Indo-European languages must certainly have developed the feature of forming the numbers 11-19 in a different way from the other sets of numbers (21-29, 31-39, 41-49, etc.) due to the influence of neighboring languages with vigesimal systems: we will call this the vigesimal-effect. This could be a clue to the location of the Original IE Homeland in India, since the eastern half of India is riddled with languages having vigesimal systems (from Sikkimese in the north through Savara and Turi in the central parts to Nicobarese in the eastern islands), and we also have Burushaski in the north-northwest – but then of course we also have the Caucasian languages in the area of the Caucasus mountains and Basque in western Europe, which (with possibly related now-extinct languages spread out in the intervening areas) could likewise have influenced proto-IE in other suggested Homeland-theories.
But the Indo-European number system nevertheless does point towards an Indian Homeland and Out-of-India theory. This can be examined from two angles:
1. The stage-wise development of Indo-European numerals.
2. The spread of the vigesimal-affected decimal number-system.
1. The Stage-wise Development of Indo-European numerals:
The first stage of the Indo-European number system is represented by the Sanskrit numbers, which are as follows:
1-9: eka, dvi, tri, catur, pañca, ṣaṭ, sapta, aṣṭa, nava
tens 10-90: daśa, viṁśati, triṁśat, catvāriṁśat, pañcāśat, ṣaṣṭi, saptati, aśīti, navati, śatam
Other numbers: unit-form+tens.
[The tens do not undergo any change in combination, with the sole exception of the word for 16, where –daśa becomes –ḍaśa in combination with ṣaḍ-. And, by the regular Sanskrit phonetic rules of sandhi or word-combination, in the unit-form+tens combinations for 80-, a-+-a becomes ā, and i-+-a becomes ya, so 81: ekāśīti, 82: dvyaśīti, etc].
Units forms:
1 eka: ekā- (11), eka- (21, 31, 41, 51, 61, 71, 81, 91).
2 dvi: dvā- (11, 22, 32), dvi- (42, 52, 62, 72, 82, 92).
3 tri: trayo- (13, 23, 33), tri- (43, 53, 63, 73, 83, 93).
4 catur: catur- (14, 24, 84, 94), catus- (34), catuś- (44) catuḥ- (54, 64, 74).
5 pañca: pañca- (15, 25, 35, 45, 55, 65, 75, 85, 95).
6 ṣaṭ: ṣo- (16), ṣaḍ- (26, 86), ṣaṭ- (36, 46, 56, 66, 76), ṣaṇ- (96).
7 sapta: sapta- (17, 27, 37, 47, 57, 67, 77, 87, 97).
8 aṣṭa: aṣṭā- (18, 28, 38, 48, 58, 68, 78, 88, 98).
9 nava: ūna- (19, 29, 39, 49, 59, 69, 79, 89), nava– (99).
Compared to the modern Indo-Aryan forms:
a) The Sanskrit numbers with –5, –7, –8 and even –9 are remarkably regular (compare with the forms already shown in Hindi, Marathi and Gujarati, for example).
b) The variety of forms for –4 and –6 are fully explained (except perhaps the ṣo- in 16) by the regular phonetic rules of Sanskrit sandhi: r- becomes ḥ- before -p (54), -ṣ (64) and -s (74), s- before -t (34), and ś- before -c (44). Likewise, ṭ- becomes ḍ- before voiced consonants and vowels (26, 86) and -ṇ before nasal consonants (96). These are all variations based only on the general phonetic rules of sandhi in Sanskrit (which apply to all Sanskrit words).
c) So we are left with with a few (far fewer as compared to the modern Indo-Aryan languages) variable forms for –1, –2 and –3 (apart from the irregular form for 16 already mentioned), and hardly any fusion and irregular inflection beyond the rules of regular sandhi.
Certain noteworthy features of the Sanskrit numbers, which have lingered on in modern Indo-Aryan, are:
1. The units come before the tens in all the numbers: this feature continues in the modern Indo-Aryan languages, and in some of the Indo-European languages outside India (Pashto under the influence of neighboring Indo-Aryan, and the Germanic branch languages German-Dutch-OldEnglish-Norwegian-Danish), but is reversed in all the other modern languages (including the Germanic branch languages English-Swedish-Icelandic) in the numbers after 20. In Ancient Greek and Latin, both ways were allowed after 20.
2. A minus principle (ūna- “less-than” or alternately ekona- “one-less-than”) is used for the -9 numbers: 19: ūna-viṁśati (or ekona-viṁśati) etc., except for 99: nava-navati. This feature continues in the modern Indo-Aryan languages and in Latin, which takes the step further (note the Latin tendency to innovate with a minus-principle, as when adopting the Attic Greek numeral system) by having duode-viginti and unde-viginti (18 and 19) etc., and even duode-centum and unde-centum (98 and 99).[Note: Dravidian has this etymology for the number 9: e.g. Tamil on-badu (“one-less than-ten”). Here the prefix on- represents the Tamil word onṛu “one”, but also resembles the Sanskrit ūna “less” and Latin unus “one”!].
But, about two other main significant features:
1. While all the branches of Indo-European languages show the vigesimal-effect, where 1-19 are formed differently from subsequent sets like 21-29, etc. (not counting the Celtic branch with its vigesimal system borrowed from Basque), the sole exception is Sanskrit.In Sanskrit, 11, 12, etc. (ekā-daśan, dvā-daśan, etc.) are exactly similar formations to 21, 22, etc. (eka-viṁśati, dvā-viṁśati, etc.), although grammatically the Sanskrit numbers 1-19 are supposed to be adjectives, while the numbers above that are supposed to be nouns. The Sanskrit numbers, therefore, clearly represent a frozen form of the earliest Indo-European purely decimal number-system before the vigesimal-effect took place.
2. Although Sanskrit is a very highly inflectional language, and the modern Indo-Aryan languages by and large have a very-much-diluted inflectional nature, the case is the opposite in the case of the numbers, where all the modern Indo-Aryan languages have a strong degree of inflection as compared to Sanskrit in the numbers 21-99. All this shows a state of affairs which leads to the second stage [Note: The numbers from 1-4 are highly inflected in themselves in Sanskrit and have many forms, e.g. 2: dva-, dvau-, dvi-, dve-, etc. and 3: tri-, trayaḥ-, trīṇi, etc. But that is not relevant to the discussion on hand]:
The second stage of development of the Indo-European number system is represented by all the Indo-European languages outside North India, where we see the vigesimal-effect in full force. In addition, the original order of the forms is unit+tens, and there is inflection in the formation of the numbers 11-19:
1. The vigesimal-effect, with the numbers 11-19 formed differently from subsequent sets like 21-29, etc., is found in all the branches of Indo-European languages outside India.
2. The unit+tens order for the numbers 11-19 is retained in the Iranian, Albanian, Germanic, Baltic, Slavic and Italic branches, and partially in the Greek branch (fully in Ancient Greek, and partially, only for 11-12, in Modern Greek), although, among these, most of them reverse the order in the numbers after 20.
3. The distinct inflection in the numbers 1-19 (but, whether having a unit+tens order or a tens+unit order thereafter, not found in the numbers beyond 20) is found in the Iranian, Italic, Germanic and Greek (in Ancient Greek, and for 11-12 in Modern Greek, as pointed out above) branches.
Strangely, “all the Indo-European languages outside North India” includes even the Indo-Aryan Sinhalese language to the south of India which shares these features:
Sinhalese (IndoEuropean-IndoAryan):
1-9: eka, deka, tuna, hatara, pasa, haya, hata, aṭa, navaya, dahaya
1-9 unit stems: ek-, de-, tun-, hatara-, pas-, ha-, hat-, aṭa-, nava–
11-19: ekoḷaha, doḷaha, teḷaha, tudaha, pahaḷoha, soḷaha, hataḷoha, aṭaḷoha, ekun-vissa
tens 10-100: dahaya, vissa, tisa, hatalisa, panasa, hɛṭa, hɛttɛɛva, asūva, anūva, siyaya
Other numbers: unit-stem+tens. Thus the word-order for all the numbers is unit+tens.
[And, like Sanskrit and Latin (and the other modern Indo-Aryan languages which retain this feature), the number -9 is expressed by a minus-principle, where ekun– is used with the following tens-form (except, as in Sanskrit and most other modern Indo-Aryan languages, for 99)].
Thus: 21: ek-vissa, 89: ekun-anūva. Only 99 is nava-anūva. There is no minus-principle].
[Modern colloquial Sinhalese has simplified the system, or can it be that colloquial Sinhalese in fact represents an archaic remnant of the first stage, where there was a purely decimal system without the vigesimal-effect?
In colloquial speech the word-order for all the numbers is tens+unit. Even the numbers 11-19 are similarly formed in the form of tens-stem+unit, as daha-eka, daha-deka, etc.
The tens 10-100 stems: daha-, visi-, tis-, hatalis-, panas-, hɛṭa-, hɛttɛɛ-, asū-, anū-, siya–
Thus 21: visi-eka, 99: anū-navaya, etc.]
Thus, Sinhalese texts provide us with evidence missing in North India itself. Sinhalese is doubtless a treasure-house of clues to the most archaic stages of Indo-European, often giving us clues to even older stages than Sanskrit (e.g. the word watura for “water”, as in Germanic English water and Hittite watar). These clues are not recognized because of the blinkers of the AIT, which treats all “Indo-Aryan” languages (i.e. Indo-European languages native to India) as belonging to one branch which entered India in its earliest form as the Vedic Sanskrit language. Orthodox opponents of the AIT, who also want to accord primacy to the Vedic language, also adopt these blinkers.
In this second stage, therefore, it is clear that there was a vigesimal-effect where only the numbers 11-19 acquired distinctly inflected forms but not the other in-between numbers from 21-99.
This second stage of development of the Indo-European number system is not found recorded in any text or document in North India because the older Sanskrit numbers of the first stage had become frozen in form and the Prakrits are recorded from a much later post-Buddhist period in the second half of the 1st millennium BCE, long after the departure of the other branches of Indo-European languages westwards from India, and after the diffusion of the Vedic Sanskrit culture to the Dravidian South, all of which must have taken place at a point of time when the Indo-Aryan languages of the North still had a numeral system at the second stage of development.
The third stage of development of the Indo-European number system, where the number system continued to become more and more subject to inflection and fusion between the tens-forms and the unit-forms, and the inflection in the formation of compound numbers spread to all the numbers from 11-99, is found in its earliest forms in most of the Prakrits and much more so in the modern Indo-Aryan languages of North India. In this stage, all the compound numbers between 10 and 100 acquired distinct forms with fusion and inflection between the tens and units words. The numbers 11-19, which had already become distinctly inflected in the second stage, therefore got a double dose of inflection:
1. In the first stage, we see that there is barely any inflection, where the numbers 11-19 are formed just like the subsequent sets: thus 11: eka+daśa = ekā-daśa, 12: dvi+daśa = dvā-daśa, etc. Compare with 21: eka+viṁśati = eka-viṁśati, 22: dvi+viṁśati = dvā-viṁśati, etc.
2. In the second stage, which as we saw is unrecorded in India, there must have clearly been greater fusion and inflection in 11-19, but not in the later sets 21-29, etc.
3. In the third stage, we find strong inflection in all the numbers, but:
a) In the numbers after 20, the tens-forms and unit-forms are still recognizable: Hindi 21: ek+bīs = ikk-īs, 22: do+bīs = bā-īs (both do- and bā- are recognizable as forms of an original dva-).
b) In the numbers 11-19, there is a clear case of further fusion and inflection: Hindi 11: ek+das = gyārah, 22: do+das + bārah, etc., where the tens and unit elements are even more fused, inflected and changed as to make recognition of the original elements more difficult: the –r– element in modern Indo-Aryan numbers from 11-19 is difficult to recognize as a development from the word for 10. [A similar process of further inflection seems to have taken place in the westernmost IE branch Germanic, where 11 and maybe 12, at least, seem to have continued to become more inflected later, making recognition of the elements difficult: English 11: one+ten = eleven, German eins+zehn = elf (German), etc. Note also: Germanic languages are also the only modern languages outside India retaining the original unit+tens order in their compound numbers after 20].
[Note on Sanskrit vis-à-vis Prakrits vis-à-vis modern Indo-Aryan:
The earliest beginnings of the third stage can be seen in most of the recorded Prakrits. But the literary Prakrits were actually highly Sanskritized or Sanskrit-imitating approximations of the spoken forms of Indo-Aryan speech of the time, and so they do not reflect the actual state of the spoken speech of the time. Thus, for example:
a) For the number 22, Pali texts alternately use both dvāvīsati (imitating Sanskrit dvāviṁśati) and bāvīsa (similar to modern Indo-Aryan form bāvīs, etc.).
b) The Pali word, paññāsa/paṇṇāsa for 50, is closer in form to the modern Indo-Aryan word pannās for 50 than to the Sanskrit word pañcāśat for 50.But its uniform use in that form (-paññāsa/-paṇṇāsa) in all the compound unit+tens numbers (i.e. in 49 and 51-58) reflects imitation of the similar use of the word –pañcāśat in Sanskrit rather than the use of multiple forms in modern Indo-Aryan languages:
Hindi: –cās (49), –van (51, 52, 54, 57, 58), –pan (53, 55, 56).
Marathi: –pannās (49), –vanna (51, 52, 55, 57, 58), –panna (53, 54, 56).
Gujarati: –pacās (49), –van (51, 52, 55, 57, 58), –pan (53, 54, 56).
Similiarly, its uniform use of the form pañca– (5) in all the compound unit+tens numbers (25, 35, 45, etc.) reflects imitation of the similar use of the same word pañca- in Sanskrit rather than the use of multiple forms in modern Indo-Aryan languages:
Hindi: pacc- (25), paĩ– (35, 45, 65), pac- (55, 75, 85), pañcā- (95),
Marathi: pañc- (25), pas- (35), pañce- (45), pañçā- (55), pā- (65), pañcyā (75, 85, 95)
Gujarati: pacc- (25), pāã– (35, 65), pis– (45), pañc- (75, 85), pañcā- (55, 95)].
Therefore, the area of North India was home to the first stage of development of the Indo-European number system (as represented by Vedic and Classical Sanskrit, and perhaps colloquial Sinhalese?), as well as to the third stage, both of which are found only in North India, while all the other branches of Indo-European languages outside North India (include literary Sinhalese) represent the second stage. This clearly indicates that the Original Homeland of all these languages was in North India, and they migrated from India during a period when the Indo-Aryan languages of the North were at the second stage, and shared a similar vigesimal-affected decimal system.
The Spread of the Vigesimal-Affected Decimal Number-System:
As we saw, the first and third stages of development of the Indo-European decimal number system, as shown by what we have called the vigesimal-effect (i.e. where the numbers 11-19 are formed in a distinctly different way from the later sets like 21-29, 31-39, etc.), are found only in North India, and the second stage is found in all the branches outside North India (and therefore must have logically existed in North India in an intervening period, even if not recorded), shows that the Original Homeland of all these Indo-European languages was in North India.
And an examination of the areas and languages which have this “vigesimal-affected decimal number-system” leads to the same conclusion:
There are many stray languages among the thousands of native American (Amerindian) languages with decimal systems, which have distinctly different formations for the numbers 11-19 on the one hand and subsequent sets like 21-29, 31-39, etc. on the other. We saw the examples of Cherokee and Navaho, and there must be many more. The explanation for this can be the effect of neighboring languages with vigesimal systems, and there are many of them in America: we saw the examples of the Nahuatl (Aztec), Yucatec (Mayan) and Yupik languages. Likewise, we saw the example of the Kanuri language in the interior of Africa which also clearly has a vigesimal–affected decimal system, and, again, there may be many more such languages in Africa. But obviously, these remote languages of America and Africa cannot have a place in the history of the origin and spread of the Indo-European languages or number systems.
The other languages which have vigesimal–affected decimal systems are: some Uralo-Altaic languages (e.g. Finnish, Estonian), some Semito-Hamitic languages (e.g. Arabic, Hebrew, Maltese), some Austronesian languages (e.g. Malay, Tagalog), and the Dravidian languages of South India. However, barring the Dravidian languages, the following points may be noted about the other languages:
1. The vigesimal–affected decimal feature is not found in the families as a whole: thus, the other relatives of Finnish and Estonian do not have this vigesimal–affected decimal system (check Hungarian, Turkish, Mongolian, etc. earlier in this article). Nor do the other relatives of Arabic, Hebrew and Maltese (check the ancient and modern Hamitic languages, Amharic earlier in this article, and the available data on the ancient Semitic languages). And nor do the other relatives of Malay and Tagalog (check Hawaiian earlier).
2. Except perhaps Arabic and Hebrew, the other languages are clearly or arguably influenced by Indo-European languages. Check what the Wikipedia entry has to say about Maltese:”Maltese has evolved independently of Literary Arabic and its varieties into a standardized language over the past 800 years in a gradual process of Latinisation.[5][6] Maltese is therefore considered an exceptional descendant of Arabic that has no diglossic relationship with Standard Arabic or Classical Arabic, [7] and is classified separately from the Arabic macrolanguage.[8] Maltese is also unique among Semitic languages since its morphology has been deeply influenced by Romance languages, namely Italian and Sicilian“.
The Malay and Tagalog languages may have been influenced by Indian languages: S.E. Asia was under the influence of Indian culture since almost two millennia.
Finnish (and the very closely related Estonian) are known to have a large number of Indo-European (even specifically Indo-Aryan and Iranian) borrowings. Also, the word for “hundred” in Finnish is sata, and in Estonian is sada.
3. The numbers 11-19 are certainly formed differently from the later numbers in all the above languages, but in every single one of them, the tens and unit forms are not fused together (except in Maltese, which, as seen above is a dialect of Arabic highly influenced in its morphology by Indo-European languages), and so the numbers 11-19 do not require to be individually learned since they are formed by simple juxtaposition: check the numbers in all these languages detailed earlier in this article.
In sharp contrast to this, in the Dravidian languages:
All the languages have this vigesimal–affected decimal system. The tens and unit words in 11-19 are fused together by inflection.
So the Indo-European languages outside North India, and the Dravidian languages in South India, are the only families of languages in the world which share this vigesimal–affected decimal feature as a whole and in almost the same way (inflection found only in 11-19 but not after 20). Obviously this cannot be a coincidence.
[The only difference is that the Dravidian numbers 1-19 have the word-order tens+unit. This shows two things: that Dravidian was influenced by Indo-Aryan in this vigesimal-effect, but also that it did not change its original more logical word-order for the less logical Indo-Aryan one].
Generally, we find common elements between the Indo-Aryan and the Dravidian languages which are not found in the other Indo-European languages outside India (e.g. the cerebralretroflex consonants, many grammatical features and words, etc. or even words for specifically Indian flora and fauna). These are usually attributed (in most cases probably correctly) to Dravidian influence on the Indo-Aryan languages. But then a conclusion sought to be drawn from these common features is that it proves that the Indo-European homeland cannot be in India, since in that case these features should have been found in some Indo-European languages outside India as well, and so this proves the AIT (Aryan Invasion Theory) and disproves the OIT (Out-of-India Theory). But this logic is extremely faulty for two reasons:
1. The other branches of Indo-European languages, in the OIT scenario, were situated well to the west of the Indo-Aryan languages and away from any influence from the Dravidian languages of South India, and, in any case, they had started migrating out northwestwards in a very early period, around 3000 BCE. So they obviously did not participate in any common Indo-Aryan-Dravidian linguistic innovations in the interior of India, or get affected by any Dravidian features.
2. The example of the purely Indo-Aryan Romany (Gypsy) language of Europe – which undisputedly migrated from India just over a thousand years ago, but did not take with it either the retroflex consonants, or Dravidian words, or words for specifically Indian flora and fauna – shows the faultiness of this logic.
But in this case, we find the common element is between the Dravidian languages of South India and the Indo-European languages outside India, and it is not found in either Sanskrit or the modern Indo-Aryan languages of North India!
We get a clear picture of a decimal number system developing in a core area in North India, occupied by the Indo-European languages which were spread out in a sprawling area between the Austric languages in the east and Burushaski in the north-northwest:
1. In the first stage, the number system which developed was a purely decimal system, which became frozen or fossilized in the Vedic language and in later Sanskrit.
2. In the second stage, this system continued to evolve and was influenced in its further evolution to a small extent by the surrounding vigesimal number systems, and developed into a vigesimal-affected decimal system, where the unitary nature of the numbers 1-10 was extended to the next set of ten numbers by fusing and inflecting the unit-word and tens-word numbers for 11-19 into single unitary words. This system spread out southwards to influence the formation of the number system in the Dravidian languages to the South, and spread out westwards and outwards from India with the expansion and migration of the other (then non-Pūru or “non-Indo-Aryan”) Indo-European dialects from India, which later spread out to Central Asia, West Asia and Europe. This system prevailed on the ground in the core area in North India, but the fossilized system of the first stage alone continued to be recorded in the Vedic and Classical Sanskrit texts.
3. In the third stage, after the migration of the other Indo-European dialects and the standardization of the number system in the Dravidian languages of the South, at some time in the late second or the early first millennium BCE, the system on the ground in the core area of North India continued to evolve, i.e. to become more and more unitary, with the unitary nature of the numbers 1-20 now extended to all the numbers 1-99, by fusing and inflecting the unit-word and tens-word numbers for 21-99 into single unitary words. This system came to be recorded in its earliest form in the Prakrit texts, and in more fully developed only in the last thousand years or so after the modern Indo-Aryan languages developed into literary languages.
All this constitutes one more piece of very strong evidence for the OIT and one more nail in the coffin of the AIT.
The article originally appeared here and has been republished with permission.
Explore the series Ancient Mathematics
Featured Image: Making India Online
(This article was published by IndiaFacts in 2018)
Disclaimer: The opinions expressed in this article belong to the author. Indic Today is neither responsible nor liable for the accuracy, completeness, suitability, or validity of any information in the article.